报告摘要
➤ 深度学习模型2024年年初波动较大,本报告提出三类解决方案提升风险控制能力。
因为资金面震荡,微盘股表现不佳等原因,传统深度学习因子二月初多空回撤超过20%,波动明显。本报告尝试了三个试图提高深度学习稳定性的方法以增强其应对风险的能力:
1.通过对高频数据的引入,提高模型颗粒度以更快应对市场异常;
2.在模型中加入风格控制,减少对风格轮动的学习,约束风格暴露;
3.使用元增量学习方法,提高模型敏感度。
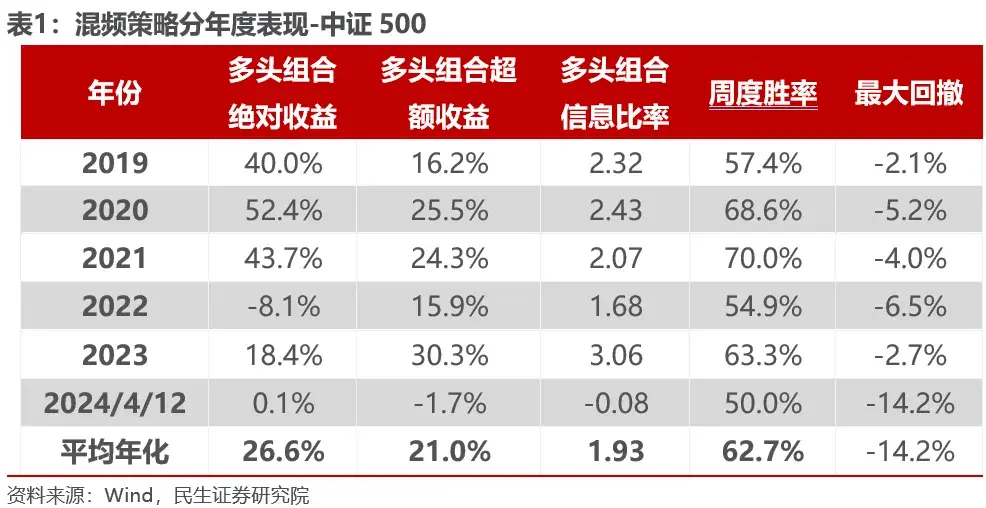
➤ 方案1:高频行情输入优化交易提升了收益但对回撤控制作用有限。
我们采用过去五个交易日的五分钟高频量价数据,预测未来2个交易日的股票收益排序。高频输入的深度学习因子日度RankIC均值0.087,在宽基指数内IC衰减降低。用高频信号对日频信号策略进行调仓优化,优化后混频策略在中证500,中证1000内年化超额收益分别提升4.6%,4.9%,但跟踪误差均无明显变化,且今年回撤仍然较大。故由于高频输入对3σ外的风险限制能力有限,且单日的交易优化无法避免组合持续回撤的趋势,无法显著控制组合回撤。
➤ 方案2:在模型中加入风格惩罚,控制模型风格暴露,降低风险。
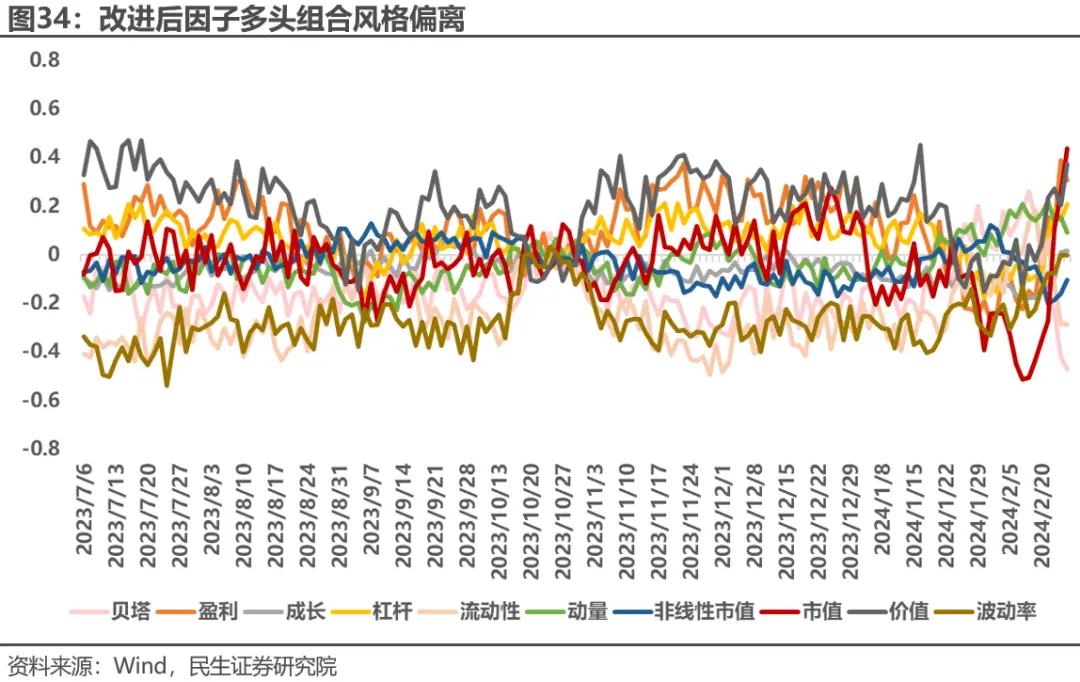
深度学习因子在2023年下半年通过在价值,盈利,波动率,流动性等因子上的暴露获得了一定收益,2024年初,因子风格发生剧烈波动,在2月份突然偏向小微盘,并且在贝塔,市值等因子上与市场走势完全相反。模型在此期间进行了错误的风格择时,很大程度上导致了因子表现的回撤。故我们可以通过在模型中加入风格因子及风格动量的嵌入,以及在损失函数端加入关于风格偏离的惩罚来进行风险控制。改进后因子RankIC有一定降低,但中性化因子的IC衰减显著优于改进前模型,多头组合年化收益有所降低,但信息比率显著提升**。**
➤ 方案3:沿用元增量学习框架可进一步控制模型回撤。
鉴于元增量学习具有对于市场变化快速适应的能力,我们可以将这一框架与模型进行结合。将底层模型改为加入风格输入后的ALSTM模型,并在损失函数中加入风格偏离的控制,在外层沿用上一篇研究中提出的元增量学习框架。最终策略在中证500上信息比率提升0.5,在中证1000上信息比率提升0.4,并且2024年均已取得正向超额收益。重新对模型多头端进行风格分析,发现模型的风格偏离降低,且风格波动减小,帮助模型控制了风险。
➤ 综合来说,应用加入风格惩罚的元增量学习模型可以较好地控制模型回撤。
在本篇研究中,针对深度学习模型在今年年初波动过大的问题,我们尝试了3种控制模型风险的方法,对基模型进行改进。分别为加入高频数据输入,在模型中添加风格因子,风格动量嵌入与风格惩罚,以及应用元学习框架进行增强。最终通过对前三篇研究成果的同时应用控制了模型风险,构建了兼顾收益与风险的深度学习策略。
➤ 风险提示:量化模型基于历史数据,市场未来可能发生变化,策略模型有失效可能。
01 传统深度学习模型风险显露
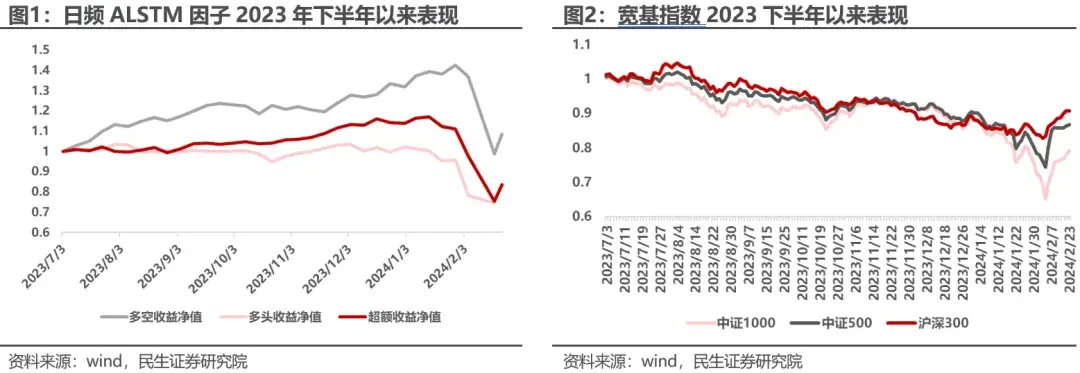
尽管传统深度学习模型有着出色的历史表现,但是在2024年一月下旬至春节前出现了较大回撤。 深度学习由于其历史上的优异表现,已经被广泛应用于投资组合构建。然而,随着深度学习在小盘风格上的暴露逐渐增加,深度学习模型的风险也渐渐显露。在2024年2月初市场风格波动明显的情况下,传统深度学习模型因子的多空收益回撤超过20%。尽管在节后反弹明显,但截至4月中旬,因子多头组超额收益仍然没有回正,对很多投资者产生了较大影响。
针对深度学习模型的风险控制,本篇研究尝试了三个试图提高深度学习稳定性的方法以增强其应对风险的能力:
-
通过对高频数据的引入,提高模型颗粒度以更快应对市场异常;
-
在模型中加入风格控制,减少对风格轮动的学习,约束风格暴露;
-
使用元增量学习方法,提高模型敏感度。
日频ALSTM因子多头组合在2024.2月初回撤较大。 主要原因为市场出现的资金面踩踏及微盘股的巨幅下跌。深度学习因子在大幅暴露小市值的情况下,较其他的量化因子出现了更大回撤,单周多空收益回撤超过20%。在春节前3天指数大幅回弹时,因子多头组合仍然下跌,表现黯淡。尽管节后有所反弹,但反弹程度仍不及指数。
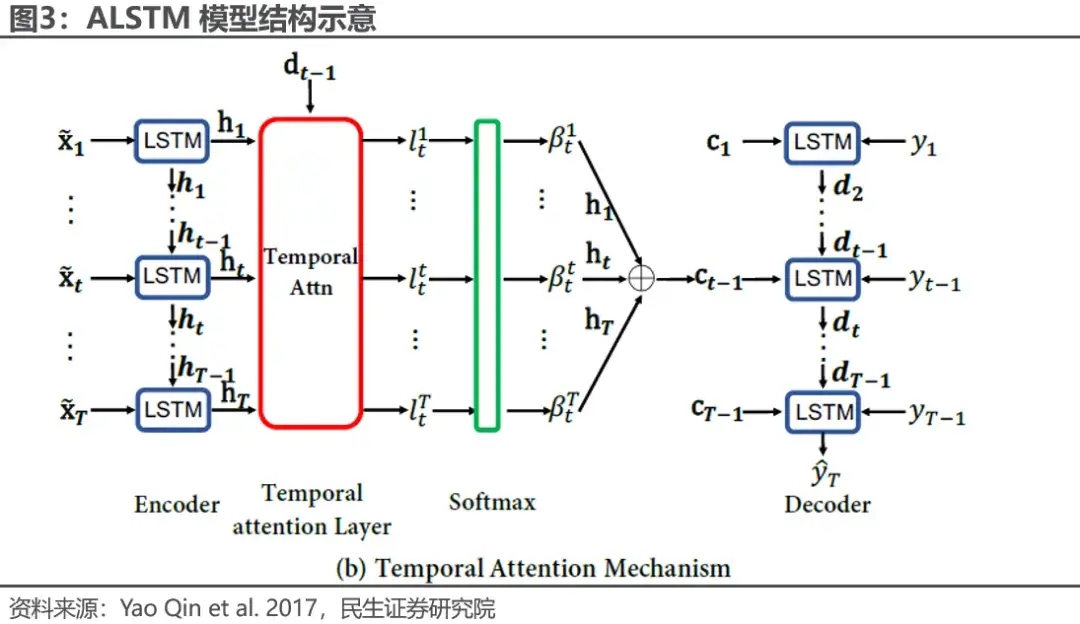
对于基模型,我们采用的是《基于可见性图嵌入的沪深300深度学习增强策略》中的DA-RNN第二步注意力机制。即时序上的注意力结构,模型旨在对每一个时间步上面LSTM隐藏层的输出进行加权,影响隐藏层的输出,同时一起输出相当于隐藏层维度的注意力权重分数。此ALSTM的模型结构如下图所示:
我们采用股票日频行情中常见的7个量价指标作为模型的输入。模型的特征处理,模型结构与训练参数如下图所示:

采用半年滚动训练的模式,每半年用过去10年日频行情数据训练模型,预测未来半年的股票收益排序。训练轮数最大100轮,最小50轮,连续20轮验证集表现无法更好即训练早停。在取每次训练的batch数据时,每五个交易日取当天的所有股票样本,即每五个交易日一个batch,训练时训练集不打乱,即按照时间顺序传播梯度,避免样本随机性过大带来的表现衰减。单样本的数据输入示意如下:
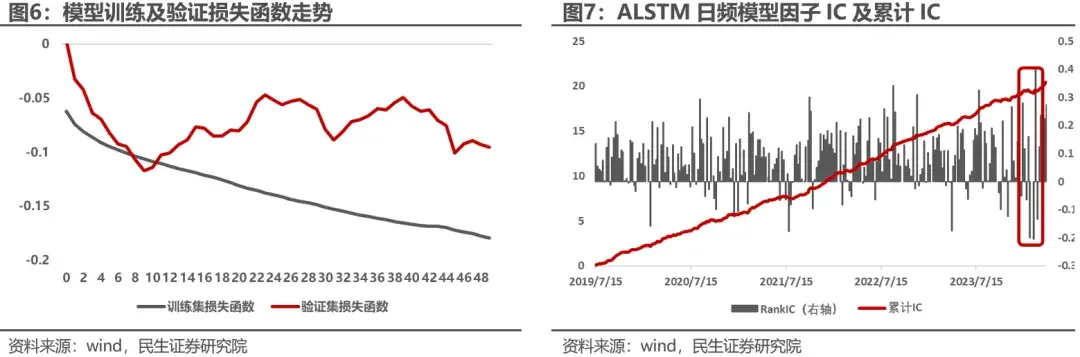
日频ALSTM因子在今年一月底至二月初的IC回撤较大。 在最近一次的训练中(训练集+验证集数据截至2023年12月31日),模型拟合较快,验证集损失函数在训练9轮左右达到收敛。每次训练取验证集表现最好的一次模型对未来半年的股票收益排序进行预测作为因子,滚动样本外因子在全A上进行回测,回测时间2019-2024.4.12,周度IC均值0.085,ICIR0.87 ,表现尚可,但在图7中可以看出因子IC今年出现了剧烈波动。
日频ALSTM深度学习因子在中证500和中证1000指数内RankIC有所降低,但今年RankIC波动较小。在中证500内周度RankIC均值0.067,ICIR0.58。在中证1000内周度RankIC均值0.072,ICIR0.68,在今年并没有出现巨幅回撤。说明在成分股不偏离的情况下,深度学习因子风险不大;即今年以来的回撤更多来自于成分股外。
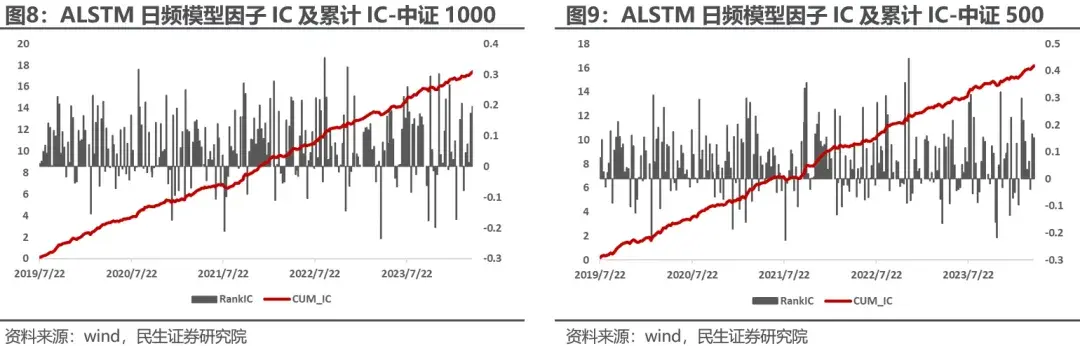
02 方案1:构造高频行情输入以优化交易策略
为了降低组合风险并提高稳定性,我们首先纳入了股票5分钟频数据集,尝试利用高频数据中的量价特征预测股票的短期收益,并将信号用于调仓优化中,以更精准的短期预测来增强组合收益,降低组合波动率。 深度学习本质上是统计模型,对于“3σ”外的极端行情,若训练时样本内没有足够的类似场景,则无法很好地应对市场的剧烈波动;而提高颗粒度可以使得日频上“3σ”外的波动分解到分钟频上“3σ”内的波动,从而有更大概率学习其中的风险规律。
2.1 用高频数据构建深度学习模型
为了足够细致地分解日频数据中的波动,且不为模型增加太大的负担,我们采用过去五个交易日的五分钟高频量价数据,预测未来2个交易日的股票收益排序。取样时,为了与调仓优化一致,我们只取过去3年每周最后一个交易日数据样本,预测周一开盘至周三开盘的收益排序。仍然使用ALSTM模型建模,单样本形状为[240, 6],并且在batch中将时间顺序打乱。模型其他细节与日频模型相同。

利用高频数据集建立的ALSTM模型在最近一次训练时在23轮左右模型收敛,模型在样本序列加长后训练变慢。 回测高频数据ALSTM模型的日频因子,模型在全A中日均RankIC为0.087,ICIR0.94,表现尚可,但因子RankIC在2月初回撤仍然较大,因子在2.1-2.8日度RankIC均值为-0.12。
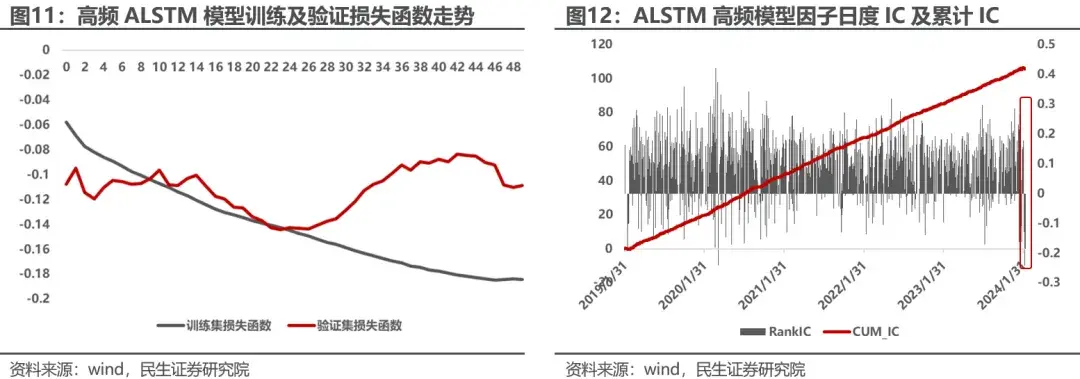
高频ALSTM深度学习因子在中证500内日度RankIC均值0.077,ICIR0.61,在中证1000中日度RankIC均值为0.079,ICIR0.7,衰减较周频模型低,且更加稳定。
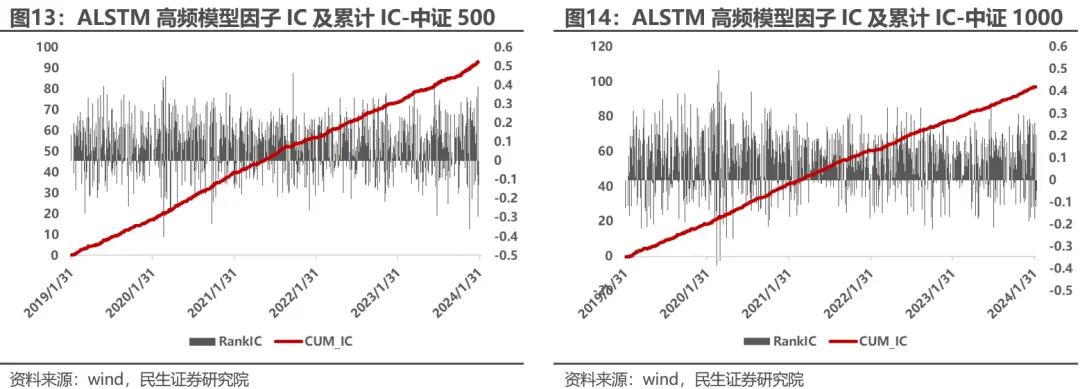
2.2 基于短期收益预测的交易优化策略
因高频深度学习因子预测窗口较短,与日频模型的标签不一致,我们不做二者在模型上的结合,而希望通过部分交易优化降低策略波动。 由于高频因子的短窗口IC较高,我们可以将其用做延迟调仓的信号,对日频深度学习因子策略进行调仓优化。具体地,我们对于因子的多头组合做如下调整。
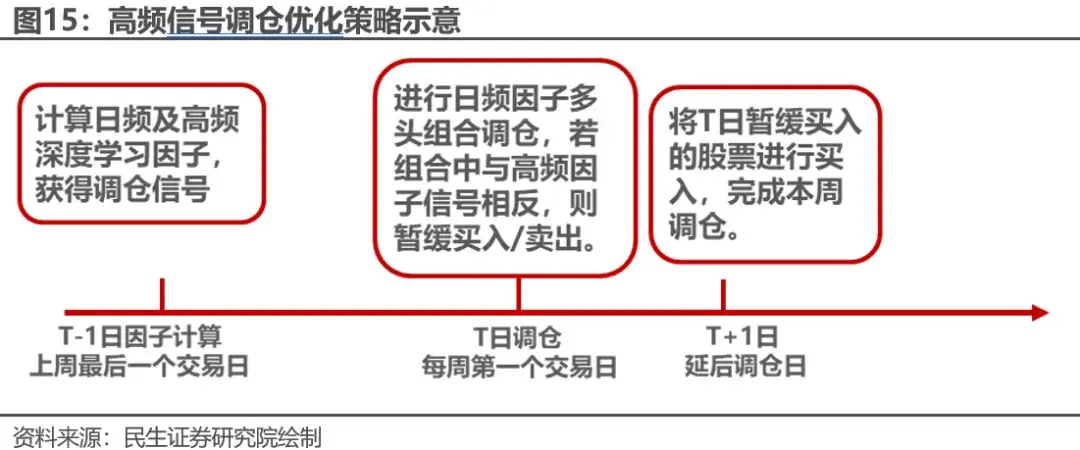
在T日调仓日,我们检查日频因子的多头组中是否包含预测单日收益Rank在排名后50%的股票,若包含,则暂缓买入这部分股票,若卖出股票中包含预测单日收益Rank在排名前30%的股票,则暂缓卖出。因高频与日频的深度学习因子在空头端相关性较多头端相关性更强,故我们将延迟买入部分阈值调高。每期延迟调仓时,若延迟买入的信号比例小于/大于延迟卖出的信号比例,则按照延迟买入/卖出信号相同的比例取做延迟卖出/买入,以保证仓位在100%不变。下图展示了平滑后的因子相关性以及延迟调仓数量占比。
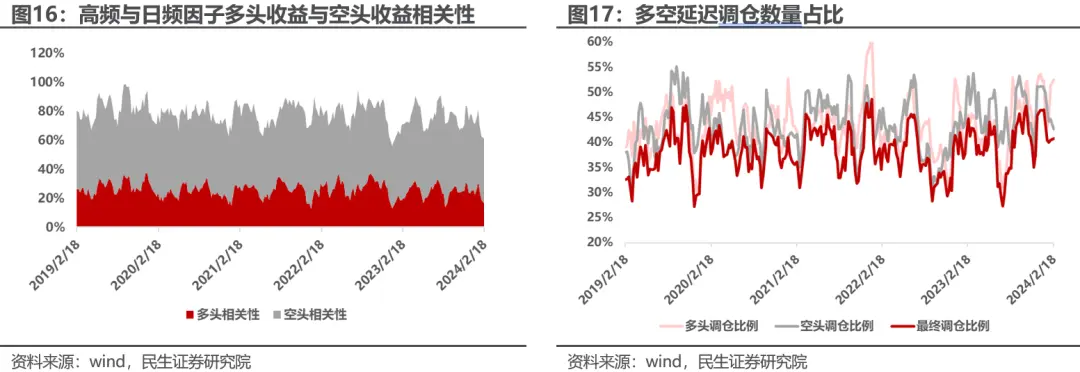
模型策略回测窗口为2019年至2024年4月12日。我们构建因子的多头等权组合,限制成分股权重70%,采用每周最后一个交易日的因子即预测值,每周第一个交易日调仓,假设用开盘价成交,交易费用取双边千分之三,我们主要观察策略在中证500与中证1000上的表现:
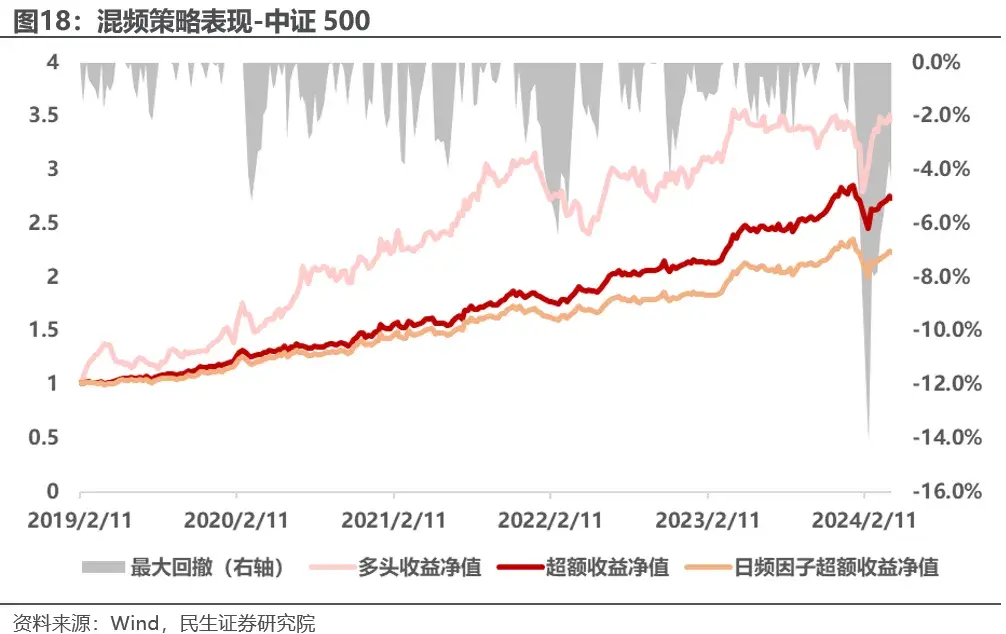
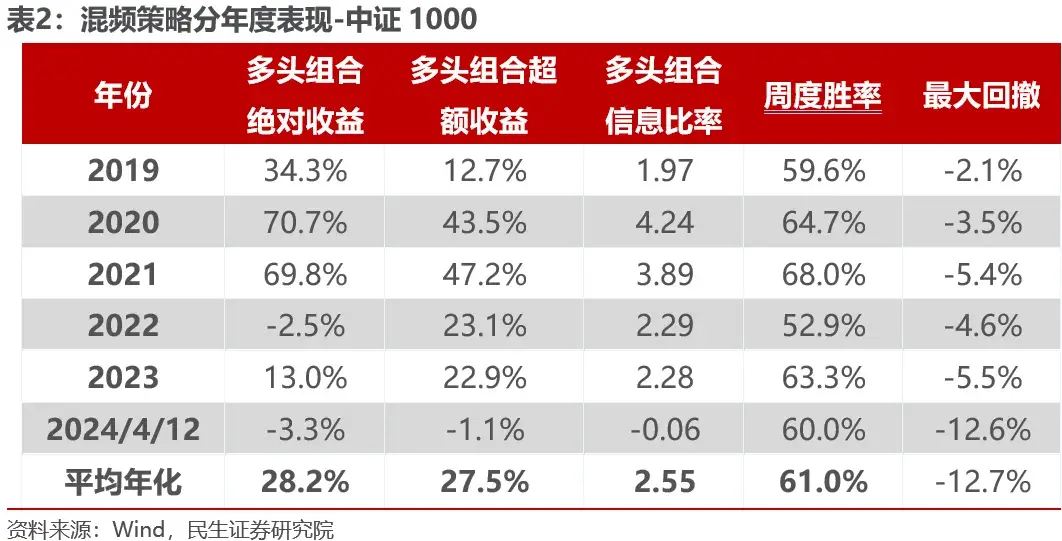
混频策略在中证500上年化收益26.6%,年化超额收益21%,信息比率1.93,加入高频信号之后年化超额收益提升4.6%左右,信息比率提升0.34,提升明显,但跟踪误差基本不变。
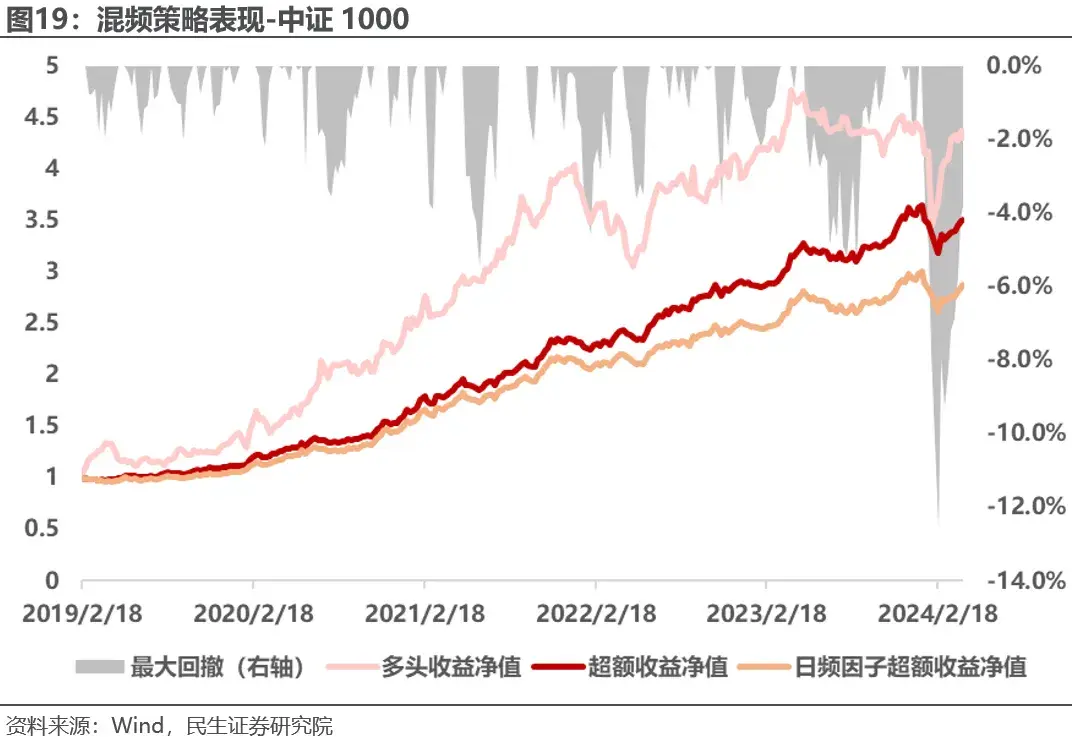
混频模型策略在中证1000上年化收益27.8%,年化超额收益25%,信息比率2.55,加入高频信号之后年化超额收益提升4.9%左右,信息比率提升0.5,提升明显,但是跟踪误差同样基本无变化。
模型周度胜率61%,策略在中证1000与中证500上在今年2月份仍然发生较大回撤,并且反弹至今仍未回正,主动风险仍然较大。总的来说,加入高频因子的交易优化策略只能通过收益的增强来提高策略整体表现,而无法避免日频样本中 “3σ”以外的波动。尤其在2月份的大幅回撤中,单日的交易优化无法避免组合持续回撤的趋势,对于风险控制作用有限。
03 方案2:在深度学习模型中加入风格惩罚
由于基于高频输入的交易优化策略对模型风险改善程度较弱,我们从日频模型本身出发,通过分析模型的风险因子暴露以及在模型中加入风格惩罚来控制模型风险。
3.1 深度学习风格波动明显
对于这次的波动行情,我们从常见的风险因子出发,选择在极端行情下更有解释能力的风格因子。分析深度学习因子多头端,即前1/5分组持仓的风格偏离,并对比近期的风格因子收益,我们发现在深度学习因子回撤的2024年一月到春节前这段时间,因子多头端风格偏离相对之前发生反转,且波动较大。
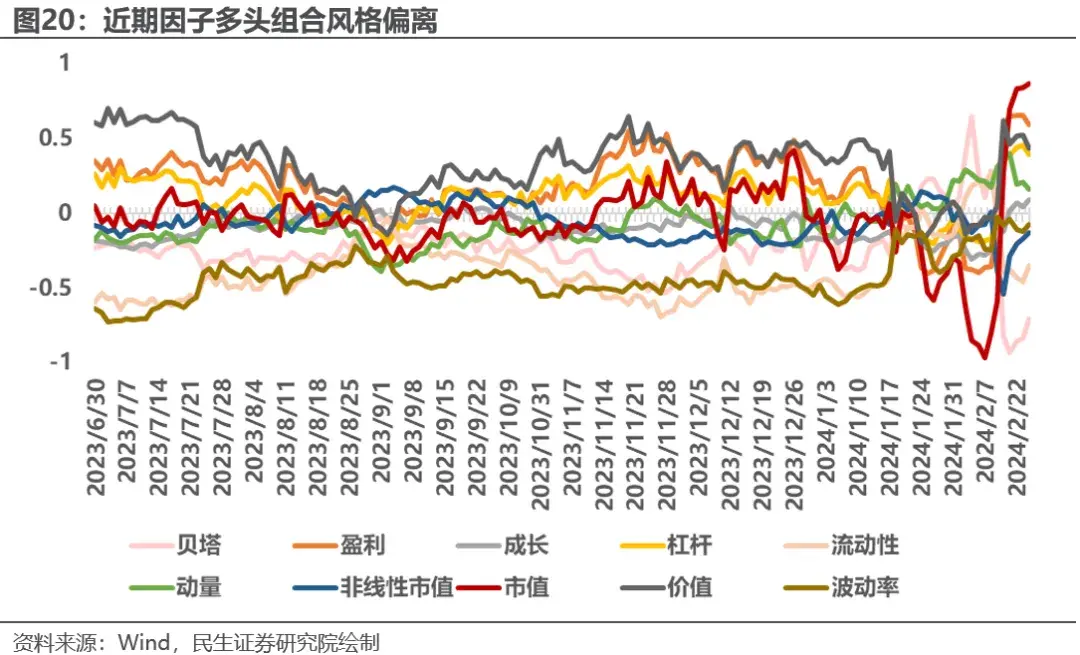
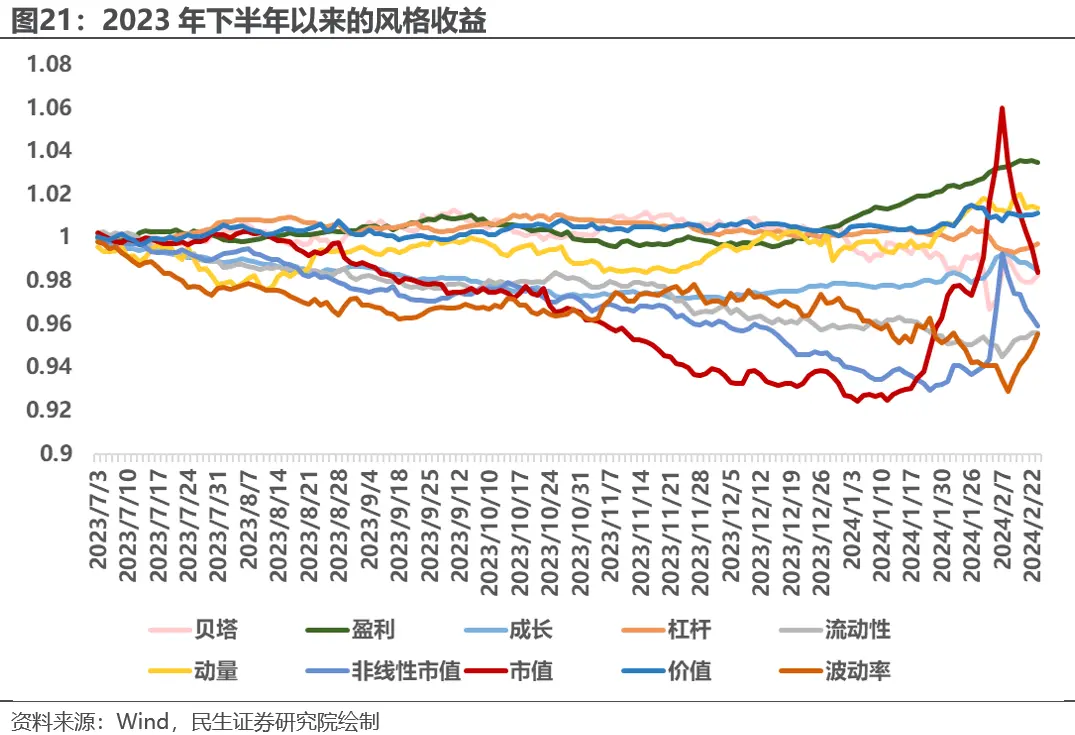
对比风格因子的市场收益,可以看出深度学习因子在2023年下半年通过在价值,盈利,波动率,流动性等因子上的暴露获得了一定收益。 而来到2024年后,因子风格发生剧烈波动,在2月份突然偏向小微盘,并且在贝塔,市值等因子上与市场走势完全相反,进行了错误的风格择时,很大程度上导致了因子表现的回撤。
3.2 通过风格控制降低策略风险
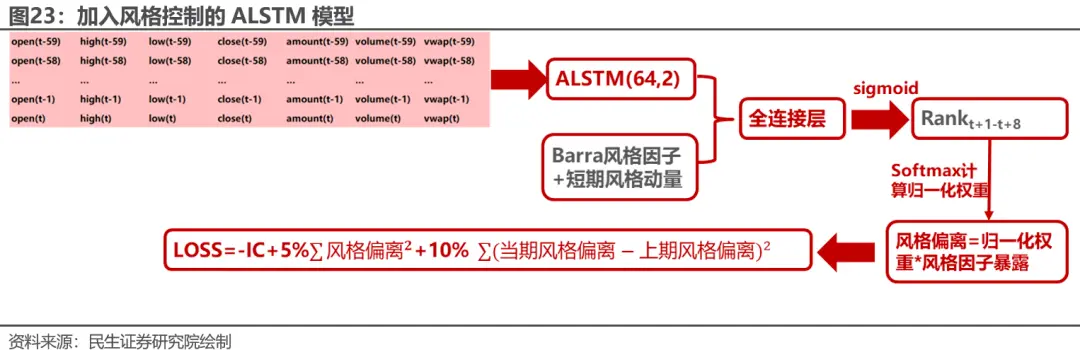
对比深度学习因子的风格暴露,我们发现回撤较大的时刻,深度学习因子通常会发生较大的风格偏离与波动。 为了控制这一现象,一个自然的想法就是在深度学习模型中加入对于风格因子暴露的控制以及风格因子波动的控制。故我们可以将模型的输出乘以对应股票的因子暴露,一起作为output,并在loss函数中体现对于风格偏离及风格波动的惩罚。具体改进如下:
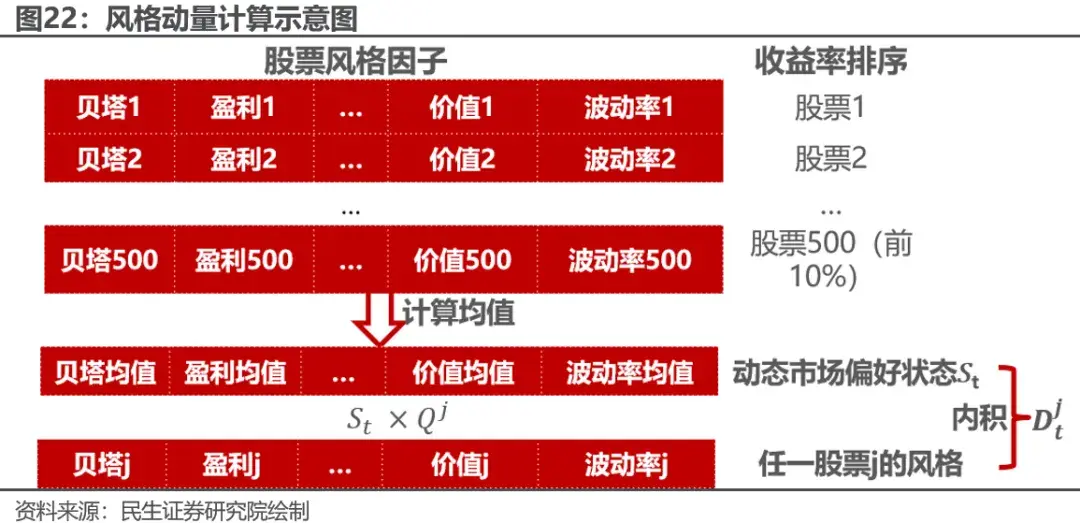
首先,在模型输入中,我们添加了10个barra风格因子作为股票静态属性输入,并且根据静态的风格因子计算动态的风格动量。这一想法正是沿用了我们在之前发布的报告《深度学习如何利用公募持仓网络优化选股效果?》中的思路。风格动量的计算方式如下:
-
首先捕捉每日动态市场状态:我们直接对每日市场上收益率最高的10%股票(剔除新股,创业板收益取一半)的风格因子向量进行平均,即可获得当前t时刻市场的偏好状态St。
-
利用获得的市场偏好对每支股票j的风格因子向量Qjt做内积,即获得了这只股票的当前市场状态Djt,Djt衡量了股票j与当期市场热点在风格上的相似度。
-
对每支股票的Djt取5日的风格平均,即得到个股的短期风格动量。
我们将10个barra风格属性与短期风格动量一起拼接至MLP中,这一拼接的方法同样沿用了上述报告中的思路,即同一因子对于股价的影响对不同种类的股票是不一样的。我们需要把股票分成不同种类,并且将分类信息作为嵌入(Embedding)输入到模型中,对神经网络的隐藏层进行增量信息的输入,达到对不同种类的股票,构建深度学习因子(隐藏层)不同权重的作用。
除了增加模型的输入端,我们还可以对模型损失函数进行修正。 具体地,我们对预测label取softmax计算一个归一化权重,从而计算当期batch预测因子的风格暴露,减去基准以得到预测的风格偏离。进一步地,由于我们在训练过程中按照时间顺序在batch中进行梯度传播,故我们可以记录上一期预测因子的风格偏离,并用本期batch风格偏离减去上期batch风格偏离,得到损失函数的第二个惩罚项。最终,我们在IC的基础上添加对于风格偏离与风格波动的惩罚作为最终的损失函数。
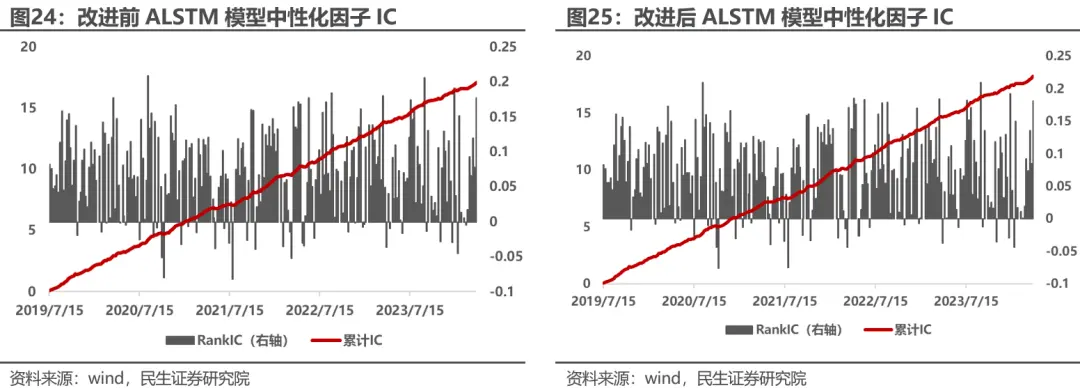
加入风格控制的ALSTM模型因子RankIC均值0.081,稍弱于原因子。但在中性化之后,因子RankIC0.075,ICIR1.24,IC减弱不明显且稳定性显著提升。而原模型因子中性化后RankIC衰减至0.071,减弱较多。 证明风格控制可以一定程度上改善深度学习对风格暴露的依赖程度,从而提高中性化因子的表现,赚取更高的特质收益。
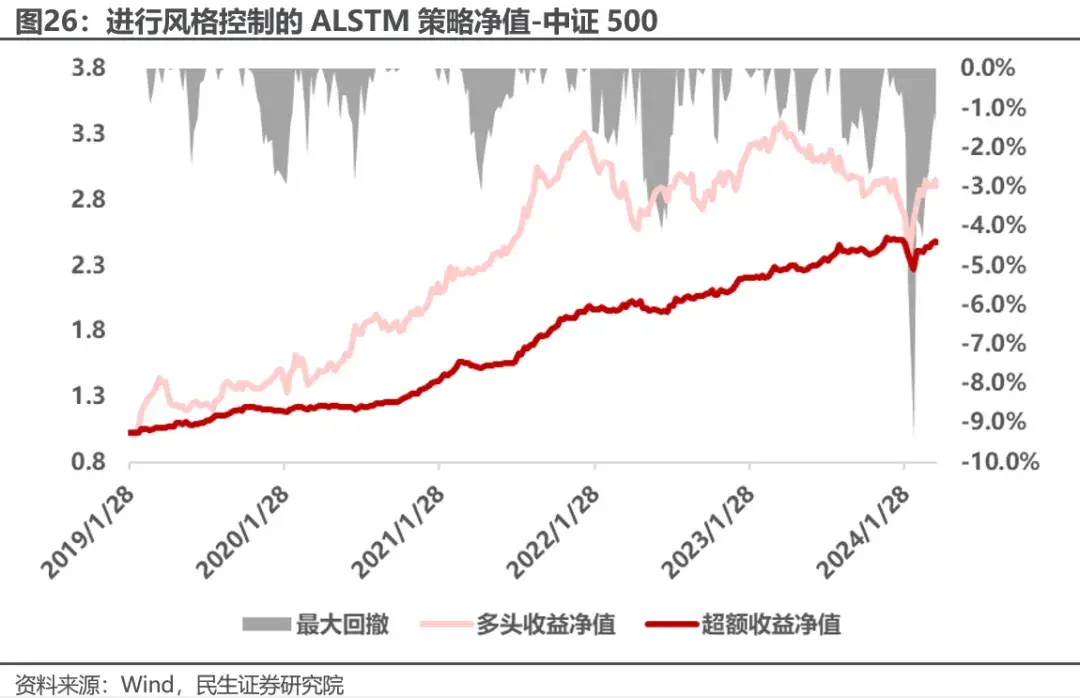
继续用进行风格控制后的ALSTM因子叠加高频深度学习信号的交易优化策略进行回测,改进后模型策略在中证500,中证1000上表现稳定性有一定提升。 策略在中证500上年化跟踪误差8.4%,相比调整前下降4.2%,2024年回撤较之前有所降低,为9.4%,仍然较大。策略总体年化超额收益18.8%,信息比率2.23,策略在牺牲一定收益的情况下提升了稳定性,达到了更高的信息比率。
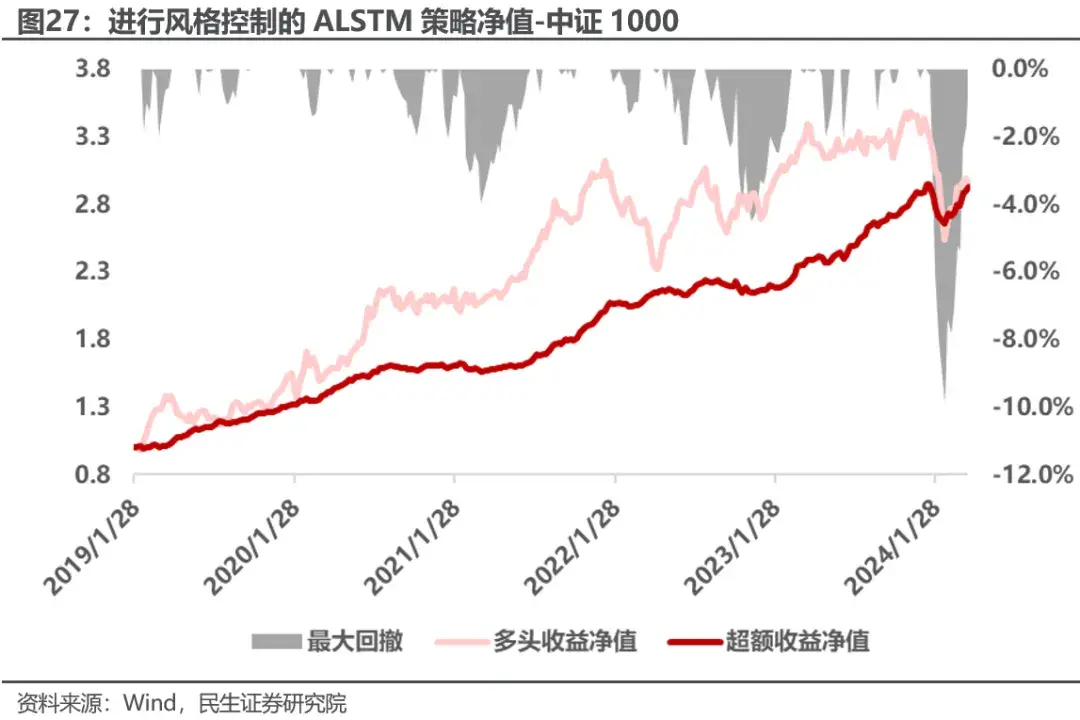
策略在中证1000年化跟踪误差7.4%,相比调整前下降2.8%,2024年回撤有所降低,至9.9%。策略总体年化超额收益22.7%,信息比率2.63,同样在牺牲一定收益的情况下提升了信息比率,达到了目标。
04 方案3:加入风格控制的元增量学习
4.1 加入元增量学习的ALSTM模型
在之前的报告《从增量学习到元学习:深度学习训练新框架》中,我们使用元学习的思想对增量学习进行提升,旨在根据最近的数据分布对数据与模型进行适应,从而快速掌握近期市场规律,适应动态变化的市场。 元增量学习首先建立在增量学习的背景之上,利用过去一段时间的增量数据来更新基模型,不断让模型纳入新的市场规律,对未来的预测产生影响。
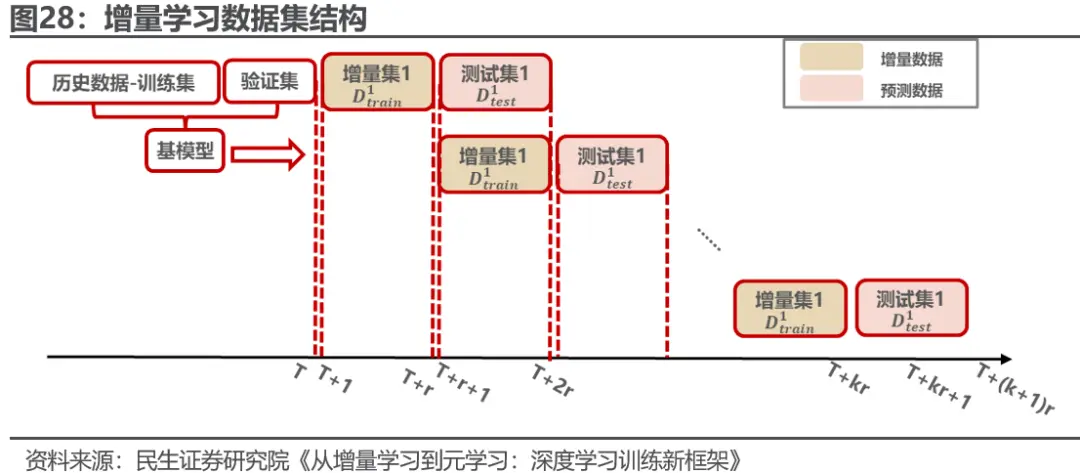
在此之上,我们可以进一步对增量数据与基模型进行适应,以避免增量数据与历史数据的联合分布差异过大导致的模型局部优化问题。 我们提出了使用数据适应器以及模型适应器两个元学习器来解决这一问题。数据适应器是一种元学习器,用来学习怎样调整训练数据的分布才能更好的适应增量数据的分布变化,以获得更好的预测准确率,其旨在通过对于任务中的X和y进行不同的多重线性变化G和H来适应数据变化。模型适应器使用了典型的元学习MAML方法,其旨在训练出一组基模型的初始化参数,以便拥有这一初始参数的基模型面对新任务时能快速学习。
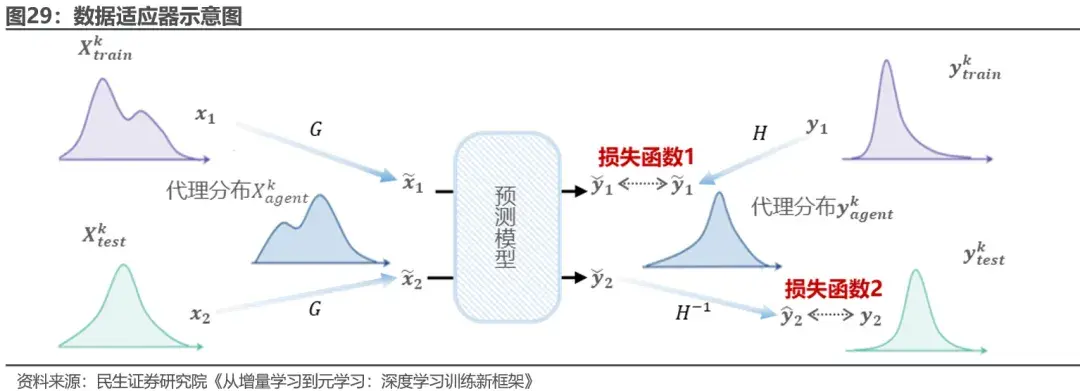
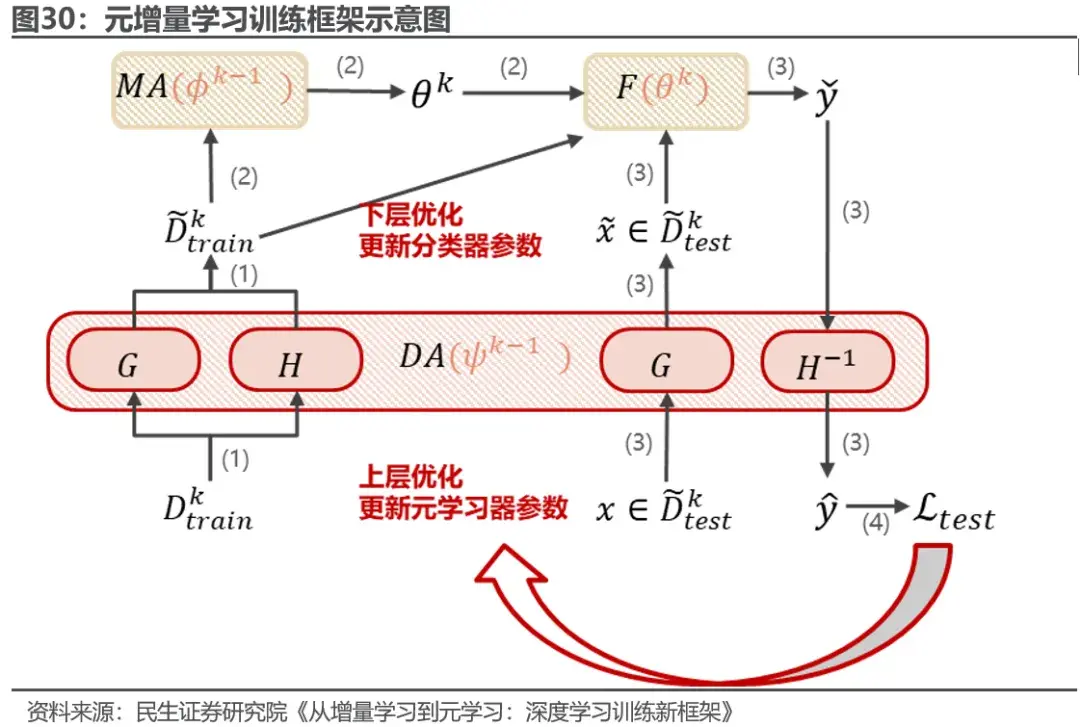
在训练时,元增量学习首先给定增量数据Dtrain,数据适应器通过G将特征向量x进行转换,并通过H转换相应的标签y,生成一个适应的增量数据集D~train,随后模型适应器通过元学习生成任务特定的参数θk,然后将更新后的预测模型f(θk)在线部署。对于Dtest中每个样本的x,数据适应器通过G将特征向量x进行相同的线性变换。然后f(θk)采用转换后的特征向量x,生成一个中间预测 ,该预测将通过H-1转换为最终预测y ̂。最后,一旦获得所有股价的真实标签,通过计算最终预测误差Ltest,在上层优化数据适应器与模型适应器,超参数从ϕk-1和ψk-1更新到ϕk和ψk,这些参数将用于下一个增量学习任务。元增量学习过程本质上是一个双层优化问题,包括神经网络的内层优化与元学习器的外层优化。模型细节请参见原报告。
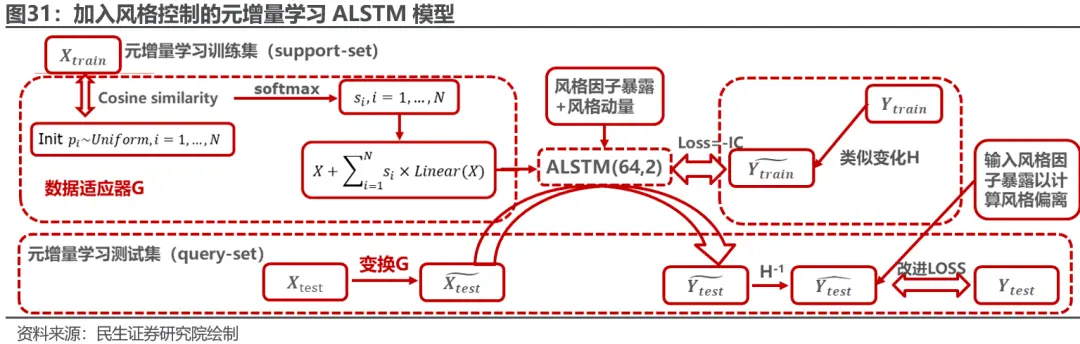
鉴于元增量学习具有对于市场变化快速适应的能力,我们可以将这一框架沿用到本篇研究中。 在上一篇报告中,我们对元增量学习在基础神经网络结构LSTM,GRU等上的应用做了初步探索。在本篇研究中,我们将底层模型改为加入风格输入与风格控制后的ALSTM模型,并将模型的损失函数由MSE改为我们在2.2中定义的损失函数。
在数据适应器时,由于股票的风格因子暴露与风格动量为拼接至ALSTM隐藏层的属性因子,故对于X的变换G只作用于原始的日频量价数据。在模型输出最终预测值y ̂后,我们对y ̂取softmax计算归一化权重,并相应计算本期预测值的风格偏离,从而计算加入风格惩罚的损失函数。
4.2 效果实证与分析
我们用最终模型得到改进因子,替换组合的周频信号,并且保持之前用高频深度学习因子得到的日频调仓信号对组合进行调仓优化,得到最终策略。 首先我们关注模型在中证500内的选股策略表现:
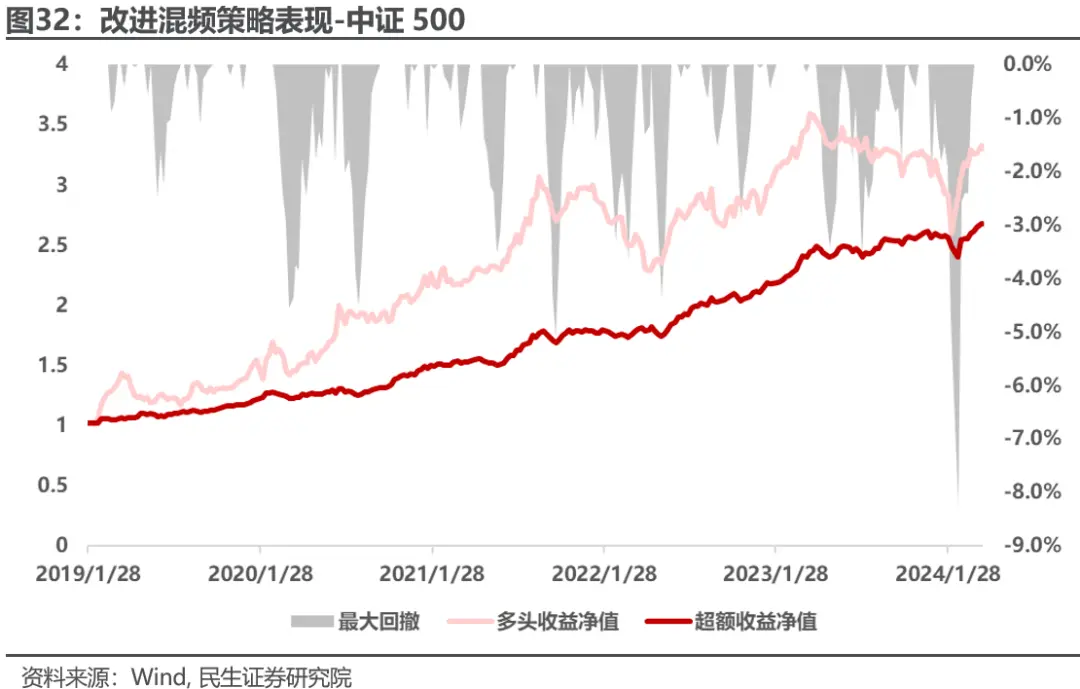
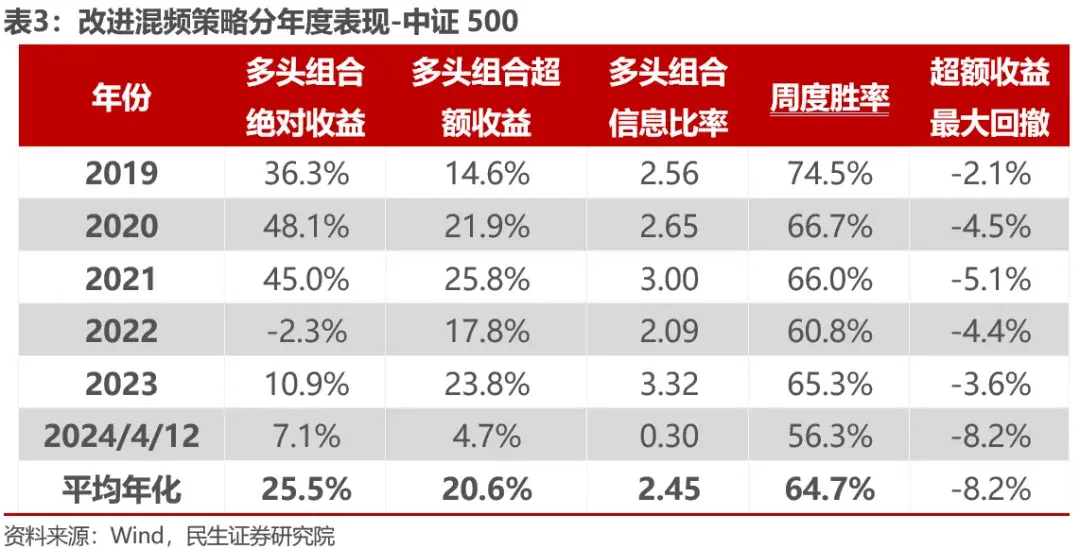
策略年化收益25.5%,年化超额收益20.6%,信息比率2.45,模型的历史稳定性有较大提升,信息比率总体提升0.5左右,并且显著缩小了策略在2024年2月份的回撤,并在2024年截至4月12日取得显著超额。
接下来我们关注策略在中证1000上的表现:
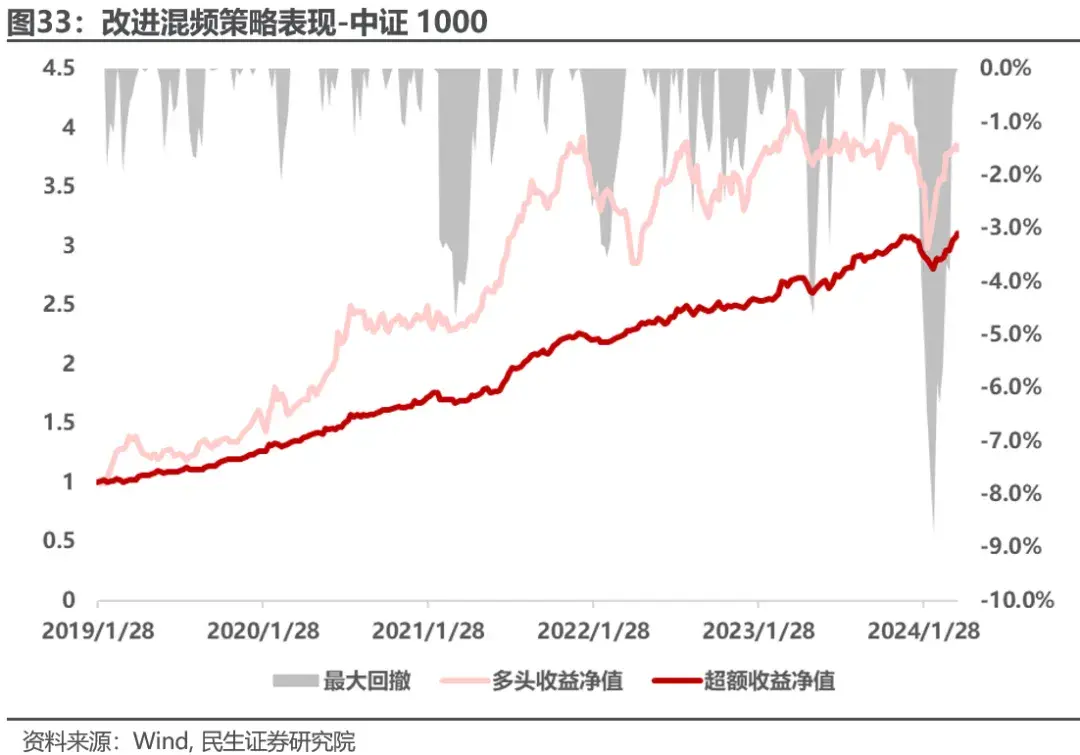
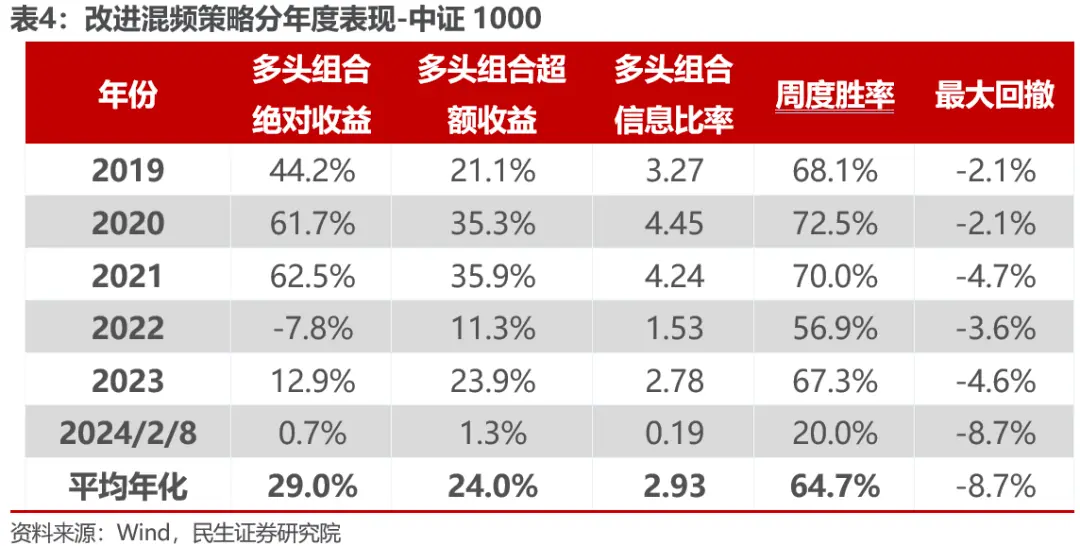
策略平均年化收益29%,年化超额收益24%,信息比率2.93,相比改进前,模型的历史稳定性同样有较大提升,信息比率总体提升0.4左右,同样显著缩小了策略在2024年2月份的回撤,并且2024年已经获得正向超额收益。
进一步分析改进后组合的风格偏离,可以发现因子总体的风格走势没有变化,但对比图21可以发现,因子在市值,流动性,波动率等因子上的风格偏离显著降低,同时风格暴露的波动率也有所降低,2月份在小市值风格上的暴露控制在了0.6左右,帮助模型稳定了策略回撤。
05 总结与思考
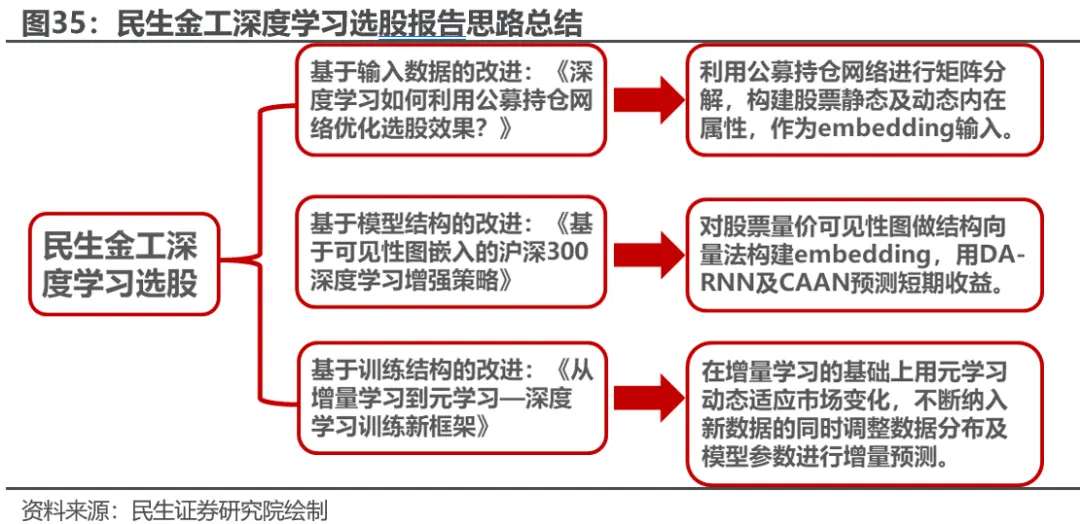
民生金工团队成立以来,已发布3篇关于深度学习选股思路探索的报告。 在之前的报告中,我们对深度学习做出了不同角度的探索与创新。在《深度学习如何利用公募持仓网络优化选股效果?》中,我们提出了基于数据输入的改进,将公募持仓网络进行矩阵分解,得到股票内在属性后,与LSTM隐藏层拼接到MLP中,对模型效果进行了提升。随后在《基于可见性图嵌入的沪深300深度学习增强策略》中,我们用结构向量法对可见性图结构信息做embedding,并且利用DA-RNN模型对embedding做处理。在最近的一篇报告《从增量学习到元学习—深度学习训练新框架》中,我们对模型的训练流程进行了改进,并且用元学习来动态适应数据分布及模型参数。三篇报告分别覆盖了中证1000,沪深300,与中证500选股域。
在本篇研究中,针对深度学习模型在今年年初波动过大的问题,我们尝试了3种控制模型风险的方法,对基模型进行改进。分别为加入高频数据输入,在模型中添加对于风格因子的控制,以及应用元学习框架进行增强。最终通过对前三篇研究成果的同时应用控制了模型风险,构建了兼顾收益与风险的深度学习策略。
首先我们采用了《基于可见性图嵌入的沪深300深度学习增强策略》中借鉴的DA-RNN模型中的第二步时序注意力ALSTM作为基模型,采用股票日频行情中常见的7个量价指标作为模型的输入。因训练集没有打乱batch,预测因子表现一般,周度IC均值0.085,ICIR0.87,且在中证500与中证1000内表现有所衰减。由于日频输入的ALSTM模型今年回撤较大,我们尝试利用高频数据中的量价特征预测股票的短期收益来解释日频数据中3倍σ以外的波动。采用过去五个交易日的五分钟高频量价数据,预测未来2个交易日的股票收益排序。高频ALSTM深度学习因子日度RankIC均值为0.087,ICIR0.94,在宽基指数内IC衰减较周频模型少。
由于高频因子的短窗口IC较高,我们可以将其用做延迟调仓的信号,对日频深度学习因子策略进行调仓优化。我们检查周频信号的多头组与空头组中是否包含预测单日收益较低或者较高的股票,若有则暂缓买入或卖出。混频策略在加入高频信号之后年化超额收益提升明显,但在今年的回撤仍然较大。主要是因为高频因子只能对局部短期收益进行更精准预测,无法稀释日频数据中的“3σ”以外的波动。
对比深度学习因子多头端风格偏离与风格因子的市场收益,可以看出深度学习因子在2023年下半年通过在价值,盈利,波动率,流动性等因子上的暴露获得了一定收益。而来到2024年后,因子风格发生剧烈波动,在2月份突然偏向小微盘,并且在贝塔,市值等因子上与市场走势完全相反,进行了错误的风格择时,很大程度上导致了因子表现的回撤。故我们可以通过在模型中加入风格因子的输入以及在损失函数端加入关于风格偏离的惩罚来进行风险控制。
沿用元增量学习框架可进一步控制模型回撤。鉴于元增量学习具有对于市场变化快速适应的能力,我们可以将这一框架沿用到本篇研究中。在上一篇报告中,我们对元增量学习在基础神经网络结构LSTM,GRU等上的应用做了初步探索。在本篇研究中,我们将底层模型改为加入风格输入后的ALSTM模型,并在损失函数中加入风格偏离的控制,在外层沿用元增量学习框架。最终策略在宽基指数上的信息比率均有一定提升,并且2024年均已取得正向超额收益。重新对模型多头端进行风格分析,发现模型的风格偏离降低,且风格波动减小,帮助模型控制了风险。
本篇报告中未涉及因子在指数增强组合上面的应用,主要是因为交易优化策略在指数增强组合上实现较为复杂。未来我们将尝试混频策略在指数增强组合上的应用。
06 风险提示
量化模型基于历史数据,市场未来可能发生变化,策略模型有失效可能。
